Industrial Asset Graph Modelling in XMANAI
In the Industrial sector specifically, graph networks can describe pathways of IoT devices and sensor networks (Aggarwal, et al., 2017) in the framework of predictive maintenance, or represent associations between resources, daily workload and production in decision-making and dynamic scheduling problems (Hu, et al., 2020).
Graph data science is a sub-domain of data science devoted to the extraction of useful knowledge from relationships and structures in data. This knowledge is then leveraged, typically with the assistance of machine learning models, to answer some previously intractable questions or produce some form of prediction. To this end, the process followed can be roughly identified as presented.
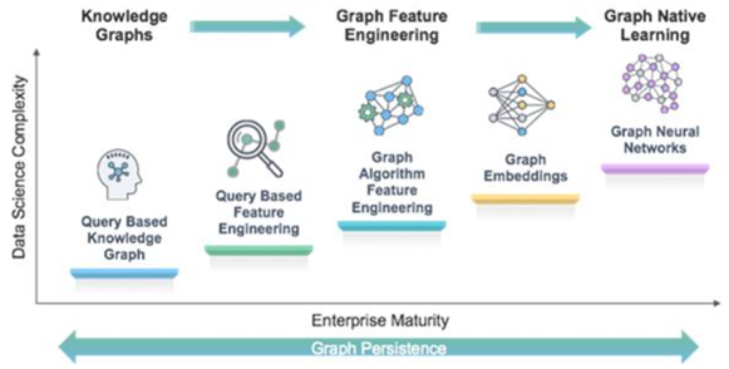
The workflow starts with the creation of a knowledge graph or some other form of graph-structured dataset derived from a knowledge base. Graphs are represented computationally using various matrices (e.g. Incidence matrix, Adjacency matrix, Degree matrix, or Laplacian matrix), with each matrix providing a different type of information. The goal is to extract latent feature representations (known as graph embeddings) of the available nodes and edges through a process known as graph representation learning (or graph feature engineering). Graph embeddings are an appropriate transformation of the graph structure that allows graph ML models (usually graph neural networks) to perform further analysis and computations by “learning” the graph topology (graph native learning).
More specifically, machine learning can solve a number of graph analytics problems that can be broadly classified into the following five categories:
- Node classification (also known as node attribute inference);
- Link (edge) prediction (often referred to as recommendation);
- Node clustering (also known as community detection);
- Graph or subgraph classification, regression, and clustering;
- Graph generation.
Graph analysis using machine learning has an increasing interest both from an industrial and academic point of view with a wide range of practical applications for graph ML. These applications can be divided into two categories based on the data available: the first category is about data where the entities and relations can be explicitly specified, like knowledge graphs or road networks, while the second category is data, where the relational structure is not clear and must be inferred or assumed, like visual scenes or text corpora, belong.
No matter how the structure is given, in order for someone to apply analytic tasks on graphs, such as classification, or clustering, it is necessary, as already mentioned, to find a mapping or representation of the discrete graph onto the continuous domain that algorithms function. This task is called “graph representation learning” and the output of the process is called graph embedding. Graph embedding methods have generally fallen into four main groups, according to their underlying techniques. The first group, distance-based approaches, aim to produce optimal embeddings by minimizing of Euclidean distances between similar nodes and are commonly used for visualization purposes. The second group is based on matrix factorization and focuses on learning network embeddings by factorizing the matrix that represents the connections between nodes. The third one, random walk-based methods, leverages random walk techniques to approximate certain properties of a graph, like a node centrality and similarity. The fourth group is related to graph neural networks and auto-encoders that aim to learn differentiable functions over discrete topologies with arbitrary structures.
After collecting all the data necessary through the partners involved in the project and following the approach described, a graph model describing the assets was created, correlating all the assets with three types of nodes: Categories; Concepts; Properties; following that same hierarchy to better describe the relationship between them. Due to the nature of the industrial environment, is also necessary to consider that the model cannot be static, needing to be capable to adapt to the new needs that are imposed by the industry.