Industrial Assets Provenance in XMANAI
The provenance of data is of high relevance due to the massive increase of data generated these days. Provenance not only plays a proper role for the web and its data, but the topic has also arrived at the analogue world. In detail, the concept of Industry 4.0, which aims to establish production chains and manufacturing processes increasingly without human involvement, has relative references to data provenance. Many production and logistics processes are to be automated by machines and require reliable data along the way.
Data provenance records are nothing more than metadata that describe the actual industrial data.
The basic idea is formulated through five questions in order to achieve the mentioned level of trust:
- Why was the data produced?
- How was the data produced?
- Where was the data produced?
- When was the data produced?
- By whom was the data produced?
The W3C PROV standard was developed by the World Wide Web Consortiums (W3C). The recommendation provides a specification to answer the above questions. In addition, existing and standardised interchange formats, such as XML and RDF, are used to achieve interoperability and compatibility of metadata with provenance information.
The core of this recommendation consists of a data model (PROV-DM) that defines a common vocabulary for data provenance. The W3C intentionally defined the model very generically to adapt it to as many use cases as possible.
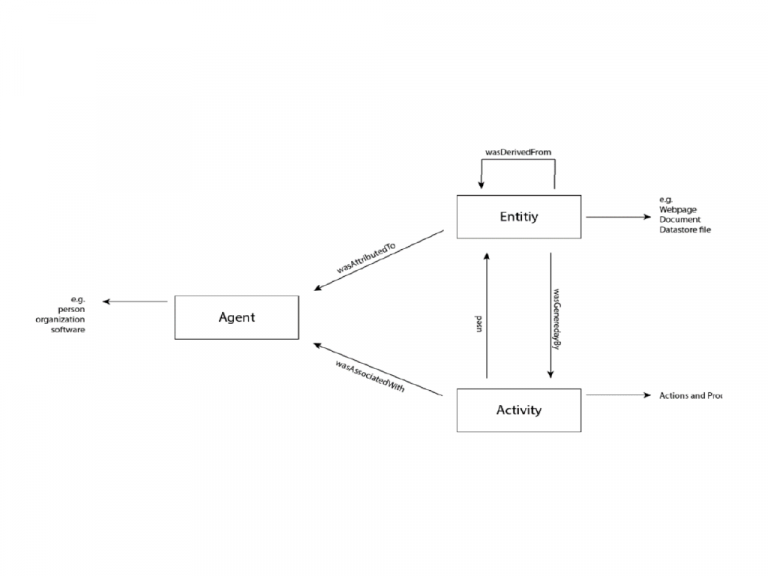
Figure 1 shows a high-level overview of the W3C PROV data model. There are three central entities: Entities, Activities and Agents. Entities define the origin; they stand for documents, a diagram, or a piece of software. They can also refer to other entities with which they are related. When content or features are transferred from one entity to another, they are derivatives of each other.
Activities represent the dynamic processes and actions that help entities change over time. For example, updates to existing records may be published, or translations of texts may be written. So new entities are constantly being created by the activities.
Agents are the roles within activities. They can be natural persons, but also a computer programme, a whole organisation or any other object. They are always bound to activities; they have a corresponding responsibility. The same applies to entities and agents. A role in this context is a description of the person or function.
One of the most important factors is time cause data can be changed over time. Changes are addressed in great detail in the W3C PROV Recommendation and are recorded separately for each entity.
Identifiers for data
The use of a persistent data identifier is one possible solution to track the origin of data. Persistent identifiers are typically unique strings, which can be an unimportant string or usually a dereferenceable URI. One approach to ID generation is the Digital Object Identifier[1] (DOI). Initially intended for online articles of scientific journals, the publisher’s inclusion indicates the origin of a document.
Another method more suitable for XMANAI is the use of URI. Each record is assigned an URI that is unique on the web. On the web, URI / URL must be unique so that resources can be found without mistakes. However, a system should be available that can check the URI of a record to ensure correctness.
Data provenance in XMANAI
Data provenance will be an important component of the XMANAI platform to enable the traceability of data accesses and modifications for all users.
A blockchain can be used to secure provenance information of data. For this purpose, a transaction is created for a block, and this block contains one identifier, a hash of the related data and the position inside the blockchain. In addition, the signature of the data provider and source information about the data are also added. If data should be traced, a hash of the data is calculated and compared with that of the blockchain. If they do not match, it can be assumed that they have been manipulated.
A blockchain is particularly suitable for a decentralised network of participants, which is not envisaged in XMANAI. For this reason, the focus is on developing an appropriate and efficient solution that is less resource-consuming.
The provenance of data and assets is realised in XMANAI by several components. Therefore, it requires close interaction between stores, i.e. database systems, and management layers, which handle the metadata.
All data, added to XMANAI, will be traceable. A persistent storage has to ensure non-interrupted versioning. This can be enabled by an asset store in combination with version management. With this approach, it is possible to version data, scripts and other commands for analyses and modelling. The asset store saves all assets and makes them available. In addition, all versions of all assets are also available and can be reproduced by the version management.
In addition, a log of emerging modifications is needed. For this purpose, the XMANAI Provenance Engine exists, which consists of a metadata handler and a triplestore. Each new version of a dataset is also stored in the Provenance Store in the form of descriptive metadata. The triplestore implements the W3C PROV recommendation, which ensures that provenance information are stored according to the standardised approach. As a result, inter-operable interchange of provenance information can be achieved. The metadata consists of information about dataset modification, versions, transactions and modifications that were executed. In addition, information about the performing entity of the respective transaction is stored. In this case, a performing entity can be a user or a computer programme, for example, when an algorithm cleans the data.
The combination of versioning and logging ensures that all data has a history and that a user can track and trace every state.
An extension of this approach is logging data accesses. XMANAI Provenance Engine is configured for this purpose. It logs which entity accessed an existing dataset. Even if the entity does not edit the data, the access should be logged as an activity.
By logging all transactions and combining it with a version history of the data, all modifications and accesses are traced. If parts of data are unintentionally removed, the engine can restore them. It is also known at which point in time and by which entity the data was manipulated in order to provide transparency and build trust in the system.
This approach means that the provenance of data and assets in XMANAI is considered from the very beginning and is taken into account at every step.
[1] https://www.iso.org/standard/43506.html