Technical Architecture and Components
Architecture
The XMANAI Reference Architecture is designed across different perspectives:
- Tiers perspective that anticipates the co-existence of the XMANAI (Centralized) Cloud Infrastructure, the XMANAI On-Premise (Private Cloud) Environments and the XMANAI Manufacturing Apps Portfolio.
- Services bundle perspective that abstracts how the data and XAI-related services are developed and integrated within 8 layers/bundles,namely the Data Collection & Governance Services, the Scalable Storage Services, the Data Manipulation Services, the XAI Pipeline Lifecycle Management Services, the XAI Execution Services, the XAI Insights Services, the Secure Asset Sharing Services and the Platform Management Services Bundle.
- Component perspective that outlines the main functionality of the different XMANAI components and how they are brought together in the different tiers and services bundles and that includes 14 components.
- Application perspective to address the scope of the manufacturing apps developed per demonstrator (4 apps in total), along with their expected interactions with the XMANAI Platform.
The following figure presents an updated, integrated version of the overall architecture containing both the service bundles and the components view.
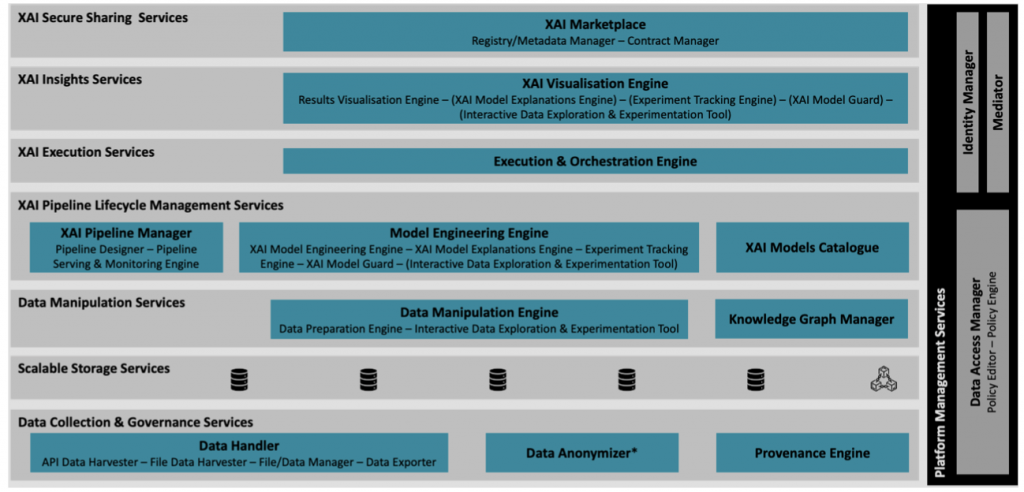
The alpha release of the XMANAI platform integrates the first official releases of the eight (8) in total services bundles of the XMANAI architecture and delivers the first set of features and functionalities of the integrated platform. Next we present a quick overview of seven (7) core operations that the user can perform through the platform:
- The data harvesting operations which are accessible through the Data Import menu item and currently enable the creation of new datasets from existing files.
- The XAI exploration and experimentation operations which are accessible through the Experimentation menu item and facilitate the exploration of the available data and the experimentation in the XAI platform’s offered notebook environments.
- The XAI application operations which are accessible through the Pipelines menu item and enable the design and execution of sophisticated and advanced AI pipelines tailored to the needs of each stakeholder.
- The asset management operations which are accessible through the Asset Management menu item and facilitate the complete lifecycle management of the assets with multiple options offered to each asset owner.
- The assets catalogue operations which are accessible through the Catalogue menu item and enable the search and acquisition of assets via the marketplace of the platform.
- The platform administration operations which are accessible through the Admin menu item and facilitate the organisation and user management activities as performed by the organisation’s administrator or the platform administrator.
- The on-premise environment operations which are currently focused only on the offline anonymisation activities prior to data import and are also listed under the Data Import menu item.
Description per User Operation
Data Import
In order for a user to make new manufacturing data available for usage within the XMANAI platform, the currently available data in the form of files in the XMANAI Assets Store should be transformed into datasets. Hence, the platform offers the option to create a new data harvesting process to create a new dataset from a previously uploaded file.
The new harvesting process will transform data from file(s) to a structured form according to the XMANAI data model. In the process, the user is prompted to perform the mapping of the dataset’s concepts to the XMANAI data model by selecting the respective concepts for his/her asset’s columns. The produced dataset will be stored in the XMANAI Assets Store for later use within the XMANAI platform.
Experimentation
The platform allows the user to experiment with data and models through a Jupyter Notebook. In this part of the platform, the user is able to view the available notebook environments he/she has configured, check their status, launch an existing notebook, or start a new notebook to experiment with.
If the user opts to create a new notebook, he/she is prompted to fill in the notebook name and select an environment either for Data Exploration or Machine Learning and Explainability. The user is guided for deciding which environment to choose by reading the descriptions that appear by hovering on the two available options. Each environment has a different list of installed python packages, depending on its use.
Once the new jupyter notebook is launched and the dataset selected, the user may start experimenting with the code, models and data through the corresponding computational document.
Pipelines
In the pipeline operations, the user is able to conceptually translate the results of the experimentation phase to XAI models and pipelines for production. This includes both Model Configuration and Model Management functionality.
By selecting the Pipeline Management option, the user can view the list of Explainable AI Pipelines he/she has configured while he/she may search for a specific pipeline, sort, and/or filter the results. Through the quick actions available for each pipeline, the user may edit its configuration, schedule its execution, view the execution logs (if available), visualize its results, or delete it. In the case of a new pipeline, besides the standard properties (name, etc.), the user needs to provide the input by selecting the dataset and defining the related action (forward, log), define incoming steps, the related block’s configuration and the action related to the output. Once the intermediate configuration is complete, he/she needs to add the output block from the Library so as to define how the pipeline’s results will be handed. At any moment, the user may preview or save the configuration, as well as proceed to the immediate or scheduled pipeline’s execution on the defined execution environment (local environment or cloud).
By selecting the Model Configuration option from the XAI Pipelines menu item, the user can create a training session so as to perform the training for a selected model to be executed within a pipeline, or create an inference session so as to use a trained model (from a list of completed experiments) and its associated explainability tool to be executed in an inference pipeline.
Asset Management
Assets can be either Datasets, Models, Results, Files or event the Data Model. Hence, the asset management operations comprises options for the user to navigate through either of these options.
In order for a user to view the list of the datasets that he/she owns or has acquired, the menu item “My Datasets” under the top menu item “Asset Management” should be selected. In this case, the user is guided into a page where each dataset that he/she owns is listed in the form of a card that contains a quick overview of the dataset’s metadata as well as a set of quick actions, including the access policies management, are available. The user is also able to use the search bar at the top of the page in order to find specific datasets, as well as easily and quickly filter the list of displayed datasets. Finally, the user I can also export any dataset via the Export button.
In case the user wishes to navigate through the AI models, he/she should access “My Models”, available under the top menu item “Asset Management”. Similar to the case of the datasets, the user is now guided into a page where each model owned (or has acquired) is listed with a similar set of quick actions available. By selecting a specific model, the details of the selected model are displayed. The user may edit the model’s metadata, access the experiment details, navigate to the training/inference sessions or define the associated access policies.
A similar interface is available for managing files, under the menu item “My Files”. In this case, the file manager of the platform is loaded and the user is presented an easy-to-use graphical interface where all his/her assets (currently only in the form of files) are listed. Besides handling file properties, the user is presented with the option to upload a new raw file into the XMANAI Asset Store which can be later used in the Data Import process explained before.
In addition, the platform also offers the ability to visualize the produced analytics results from the successful execution of an XAI pipeline. In particular, the user can select the “Visualise” quick action in order to initiate the visual representation of the produced results through a guided stepwise wizard that presents two major options to the user: a) the option to create a new visualisation from scratch, and b) the option to load an existing visualisation configuration that was previously created and saved.
Another important option offered to the user of the platform is the ability to access the semantic meta-information associated to all datasets. In particular, the user can access a visual representation of the XMANAI data model by selecting the menu item “XMANAI Data Model” under the top menu item “Asset Management”. With this option the user gets access to the data model (in a graph format) where he/she can visualize all categories, properties and relationships, as well as propose new concepts currently not listed. However this operation will require approval by the XMANAI platform administrator.
Catalogue
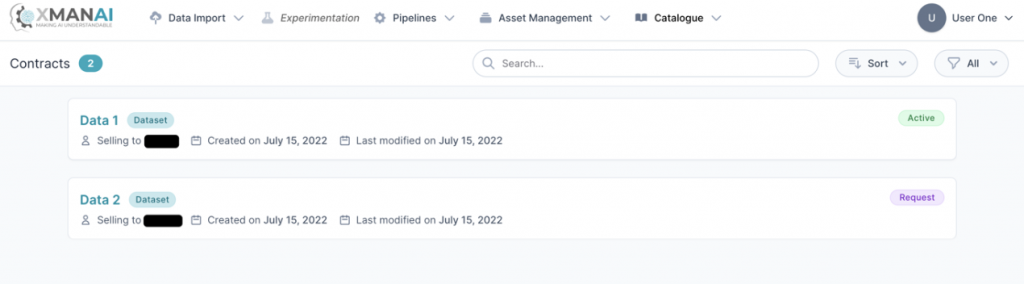
The XMANAI Platform allows users to share their assets in order to collaborate with other stakeholders from external organizations (to their own) or acquire missing data. To this end, when a user selects the search sub-menu under the “Catalogue” menu, he/she comes across the different assets that have been shared at the cross-organization level and that he/she (as the user under a specific organization) is authorised to view according to the assets’ access policies.
If a user finds an asset, he/she is interested in using or collaborating over, he/she initiates a request and provides a relevant message to the asset owner that reviews such a request and take appropriate action by offering a sharing agreement or declining the request. The XMANAI Platform allows users to view all sharing agreements in which their organization has been involved.
Organisation Management
The XMANAI platform’s functionalities and features are strictly provided only to registered users and upon their successful login into the XMANAI platform.
Through Organisation Management, the top-level user of the organization (organisation’s manager) is entitled to register the organisation in the XMANAI platform by filling in the organization’s registration form. Every new organisation request is reviewed and approved by the XMANAI platform’s administrators. Furthermore, the organisation’s manager can manage the users of his/her organisation, inviting new users, deactivating/reactivating their accounts, etc.
The users of the platform, either being an organisation’s manager or a simple user of an organisation, can always access their profile information, edit his/her profile information (except for his/her email address) or change his/her password.
On-Premise Environment
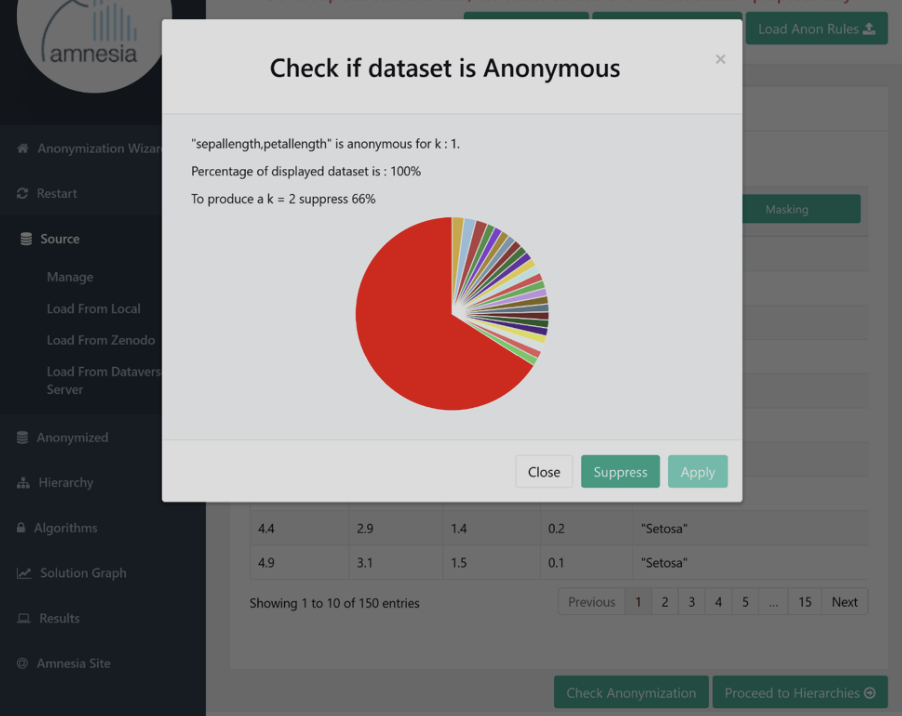
The XMANAI platform offers a novel data anonymisation tool, namely the Anonymiser that is based on the open-source tool Amnesia, which constitutes an on-premise offline tool that the user of the platform can download, install and utilise before uploading any data to the XMANAI platform.