XMANAI Provenance Engine: Tracking data provenance and data lineage
What is Data Provenance and Why is it Important?
Data provenance is akin to a comprehensive breadcrumb trail for data, tracing a dataset from its origins to consumption, and any transformations along the way. More specifically, data provenance records are metadata that tracks what changes are made to which datasets when, and by whom. Provenance information is essential in determining a dataset’s quality and reliability, thereby laying the foundation for trust in data-driven systems.
In the XMANAI ecosystem, data provenance allows for improved data quality assessments, facilitation of error detection and correction, improved compliance with regulatory standards, and improved attribution. This is particularly important in industrial settings where decisions made on AI analyses can have significant financial, operational, and environmental implications.
Improved Data Quality Assessments: The Provenance Engine provides a detailed history of each asset’s origins and transformations; moreover, this information can be used to assess assets more accurately. This in turn allows AI models to be trained on high-quality assets leading to more reliable outcomes.
Facilitation of Error Detection and Correction: The Provenance Engine meticulously tracks every change made to every asset from its inception to consumption, making it possible to pinpoint the origin of data inaccuracies. This not only improves the accuracy of assets but also the accuracy of AI models trained on them.
Compliance with Regulatory Standards: The Provenance Engine provides an auditable data trail, documenting each asset’s origins and transformations. Due to this transparency, ensuring data is handled following applicable laws can be easily verified.
Attribution: The Provenance Engine tracks which users provide which assets and how those users modify them. As such, asset ownership and modification can be easily attributed to specific users.
How does the XMANAI Provenance Engine Work?
The Provenance Engine implements W3C PROV to track data provenance in the XMANAI context. This allows the Asset Store to call the Provenance Engine whenever a user creates, reads, updates, or deletes a dataset, and for the Provenance Engine to store this provenance information as RDF. Furthermore, this provenance information can then be queried to shed light on a dataset’s origins and transformations.
W3C PROV
The W3C PROV standard was developed by the World Wide Web Consortium (W3C), providing a framework for representing provenance information.
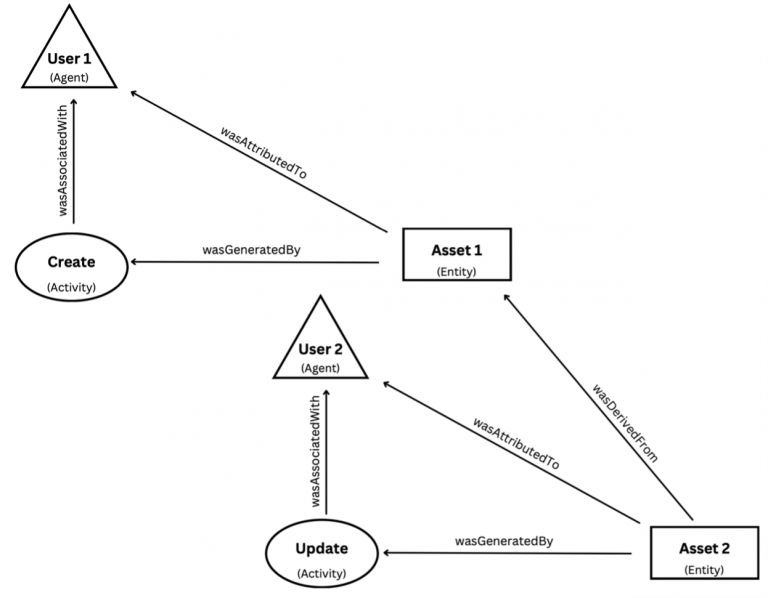
The core data model describes three primary classes: Entity, Activity, and Agent. In the XMANAI context:
Entities refer to data assets.
Activities refer to actions performed on these assets, namely create, read, update, and delete.
Agents refer to users who perform actions on these assets.
Furthermore, PROV specifies several primary properties that relate to these classes, including
wasGeneratedBy: The production of a new Entity by an Activity. In the context of XMANAI, this occurs when an asset wasGeneratedBy the user creating or updating an asset.
wasAttributedTo: The ascribing of an Entity to an Agent. In the context of XMANAI, this occurs when an asset wasAttributedTo the user who created the asset.
wasDerivedFrom: A transformation of an Entity into another Entity. In the context of XMANAI, this occurs when an asset is updated. Thus, the updated asset wasDerivedFrom the original.
wasAssociatedWith: The assignment of responsibility for an Activity to an Agent. In the context of XMANAI, this occurs when a create, read, update, or delete activity wasAssociatedWith a user.
Figure 1 displays how these core data model classes and properties interact, specifically showing the example of a user creating an asset and then a second user updating that asset.
Figure 1: W3C PROV Standard
Provenance Engine Architecture
The Provenance Engine provides an API to document user actions and retrieve provenance information.
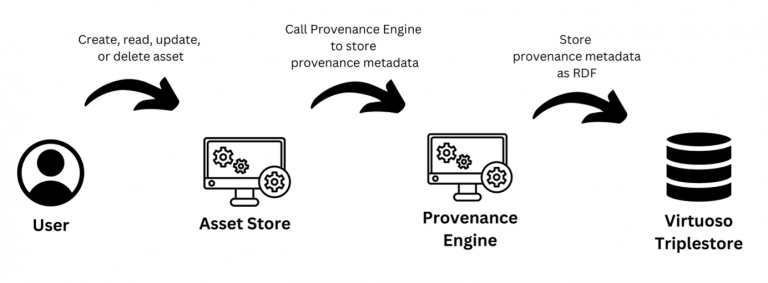
As shown in Figure 2, when a user creates, reads, updates, or deletes a dataset, the Asset Store calls the Provenance Engine’s API to store associated provenance metadata. The Provenance Engine converts this information to RDF using W3C PROV, storing it as a graph in a Virtuoso Triple Store.
Figure 2: Provenance Engine Operation Documentation API
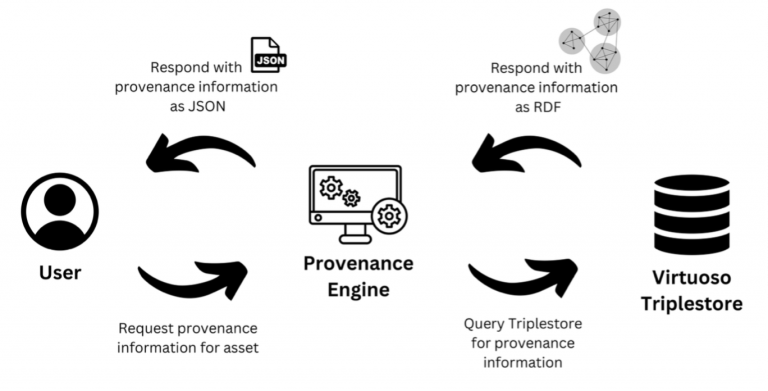
Furthermore, when a user wants provenance information associated with a dataset or user, they can also call this API, as seen in Figure 3. More specifically, the user can retrieve an asset’s history, lineage, and family tree, as well as a user’s history.
Figure 3: Provenance Engine Information Retrieval API
Final Thoughts on XMANAI Provenance Engine
The XMANAI Provenance Engine provides a foundation of trust allowing users to trace a dataset from its origins to its consumption, including every transformation along the way. This improves data quality assessments, facilitates error detection and correction, aids compliance with regulatory standards, and allows asset ownership and modification to be attributed to specific users. Given the potential for AI analyses to influence significant financial, operational, and environmental outcomes, the ability to fully trace and comprehend the data lifecycle becomes paramount. Above all, it is an essential component that aids stakeholders in producing, understanding, and learning from XMANAI’s explainable AI.
The XMANAI website uses cookies. By using our website and agreeing to this policy, you consent to our use of cookies in accordance with the terms of this policy.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.