XMANAI Validation Environment for AI Models
The Explainable AI (XAI) in Manufacturing (XMANAI) project aims to provide a framework for the development and deployment of AI models in the manufacturing industry. One of the key requirements for this framework is the establishment of validation protocols to evaluate the performance and accuracy of supervised machine learning models. Specifically, after a model has been trained, the validation process involves evaluating the model’s performance with a testing dataset. The testing dataset is a subset of the initial dataset used for training and is used to assess how well the trained model generalizes to new data.
For the XMANAI project, seven performance metrics were selected for regression and clustering learning algorithms. For regression, these metrics include the explained variance regression score, the maximum residual error, the mean absolute error, the mean absolute percentage error, the mean squared error, and the R2 score (the coefficient of determination). These metrics are used to evaluate and understand the derived regression model for each use-case and improve the model’s performance.
Moreover, a fundamental issue in learning algorithms is the selection of the hypothesis set which is known as the model selection problem. To obtain a more accurate estimation of the true risk, a validation set derived from the training data can be used to evaluate the algorithm’s output predictor. Resampling methods, such as cross-validation and bootstrap, are used to estimate the prediction error of a machine learning algorithm and evaluate its performance. Particularly, for the XMANAI project, six validation techniques were selected based on the developers’ preferences. These techniques include Predefined split CV, K-Fold CV, K-fold iterator variant with non-overlapping groups, Repeated K-Fold CV, Leave-One-Out CV, and Time Series CV. To ensure unbiased results and improve efficiency, the training dataset is used to fit the model, and a separate validation dataset is used to evaluate the model’s performance. The validation dataset provides an unbiased evaluation of the final adjusted model’s skill and is generally used to optimize model parameters.
Since the XMANAI platform offers a wide range of validation protocols to help developers determine the best approach for their use cases we created a guide for the validation protocols. Specifically, because there is no one-size-fits-all validation method, a flowchart is used to guide the selection process based on the learning algorithm type, the number of observations/records, and the data type. The validation protocols involve applying specific performance measurements, such as the explained variance regression score, maximum residual error, and Silhouette Coefficient, among others. If the expected data size is 40,000 observations or more, the hyperparameter selection process is performed on the validation set, otherwise, on the training set. Depending on the type of data, validation techniques such as the predefined split CV, K-Fold CV, Leave-One-Out CV, and Time Series CV may be used. It is important to note that the Leave-One-Out CV is not recommended for large datasets as it is time-consuming and computationally expensive. The flowchart helps developers understand the validation process better and enables them to select one or all of the mentioned K-Fold CV techniques, making the selection process more tailored to their specific use case.
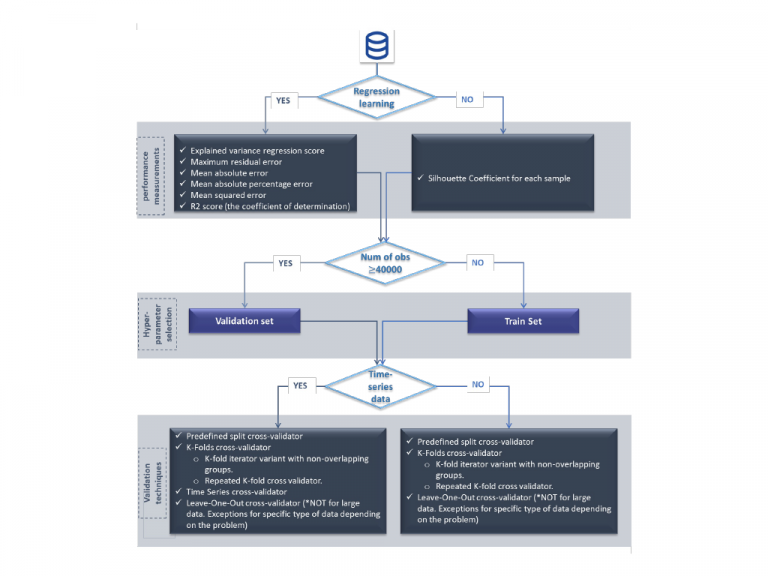
In conclusion, the XMANAI validation environment for AI models is essential to evaluate the performance and accuracy of supervised machine learning models. The validation protocols and associated performance metrics, as well as the selected validation techniques, enable the development of accurate and efficient AI models for the manufacturing industry.