Intelligent ETL Solutions for XMANAI: API- and File Data Harvester
ETL and why it so important for (X)AI Applications:
Data is a driving factor when it comes to the growing impact of AI across all domains. As more and more industries want to benefit from the current development and adopt AI-products in order to accelerate their businesses, intelligent solutions for the processing and transportation of data, also referred to as ETL (Extract Transform Load) become increasingly relevant. The manufacturing domain, which as part of the Industry 4.0 evolution is currently on the point of entirely transforming in various fields, such as machine maintenance, quality assurance or production planning, has special interest in this aspect.
The XMANAI Platform, as it constitutes an Explainable-AI-Solution dedicated to help businesses in manufacturing adopt AI into their processes, therefore has to provide efficient mechanisms for integrating initially external data into the XMANAI realm. This harvesting process does not only include the transport of the data but also its conversion to the XMANAI data model. Only this way, the data can be used for further internally operating processes like the training of AI models.
While the sensitivity of the data requires the harvesting process to be secure, the individual nature of different data sources inherits the need for flexibility. At the same time, depending on the specific use case, the datasets to be integrated into the platform may be very large and require frequent updating, which calls for efficiency and automation.
Integrating ETL pipelines into XMANAI
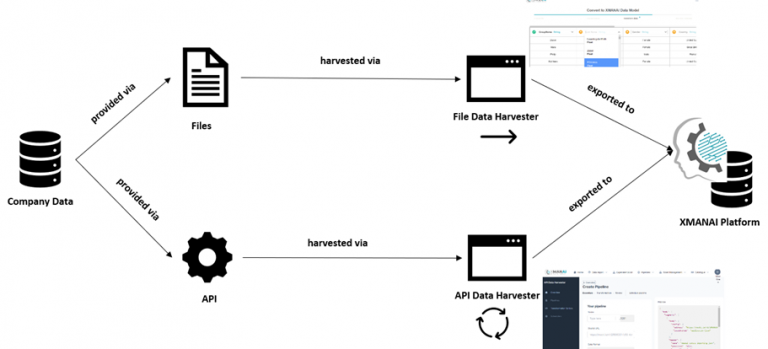
In order to tackle this task, the XMANAI Platform will provide two individual data harvesting tools, specified on different use cases:
As the name suggests, the File Data Harvester is dedicated to extract data from files. It offers an intuitively operable UI, which step by step guides the user through the process of selecting, transforming and finally storing the desired data. This guidance includes an automated recognizing of the involved data types as well as a “data type alignment check” within the transformation procedure. This feature helps the platform to achieve its goal of keeping humans in the loop by providing accessibility also to those people, who have less knowledge in data related fields. It supports multiple file types, is fast and easy-to-use.
The API Data Harvester on the other hand provides the possibility to configure pipelines, which, once set up, automatically harvest data from a desired (API-)source. Thus, instead of harvesting the data himself, the user instead creates and manages the harvesting processes, which are being executed automatically in the background. He can create triggers, allowing for a cyclic updating of the data without further ado and ensuring that the XMANAI platform is always provided with the latest data. The embedded technology allows for several pipelines to be executed in parallel, providing maximum efficiency. Its modular architecture enables the API Data Harvester to adapt to different data sources easily, ensuring flexibility. Just like the File Data Harvester, it offers a UI, providing step-by-step workflows to create pipelines, a clear overview of all pipelines and their respective status as well as an individual logging monitor and health check for each individual pipeline.
The following graph provides an overview of the possible steps through which data can be harvested and integrated into the XMANAI platform: