Explaining Transformers
Transformers are neural network architectures that have delivered performant solutions in several fields including Natural Language Processing (NLP), computer vision & audio/speech analysis. In fact, state-of-the-art NLP models such as GPT4 and BERT are built using transformer blocks.
The self-attention mechanisms upon which these models are built allow for parallel processing of the input and for the handling of long-term relations by keeping track of the most relevant context along the sequence. The use of multiple attention “heads” has revolutionized this type of architecture, enabling transformers to capture complex patterns and distant context relations. Initially designed for traditional sequence2sequence tasks, such as neural machine translation, transformers have also conquered the fields of computer vision and audio processing by exhibiting excellent performance in tasks such as image classification/generation, object identification, video processing, speech recognition and music generation. The flexibility of transformer-based networks makes them capable of handling multi-modal tasks such as visual question answering, visual reasoning, caption generation, speech-to-text translation and text-to-image generation.
The decisions and inner workings of transformers, however, are hard to interpret due to their complex architectures and multiple parameters. This limitation prevents stakeholders from adopting transformers in sensitive fields such as health, finance and industry where humans are actively involved and model decisions need to be explained. A number of researchers have contributed to rectifying this obstacle, mostly by leveraging the attention weights in different layers of the model. In this post we share a couple of these works on explaining transformers that we found very interesting.
The first is BertVis by Jesse Vig. BertVis is an open-source interactive tool that visualizes the attention weights in Transformer language models such as BERT, GPT2 and T5, while most of Hugging Face models are also supported. The tool builds on Tensor2Tensor visualization tool by Llion Jones and can be used inside Jupyter or Colab notebook environments, to provide an interactive, comprehensive view of the attention mechanism at the neuron, head, and model level.
Try out this powerful tool in this Colab tutorial and visit the github repository for more details!
Example head view
Example model view
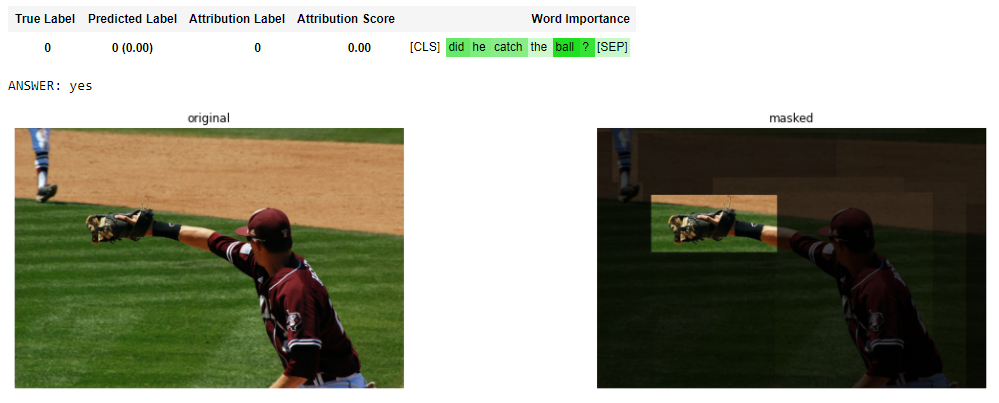
The second work on Transformer explainability that caught our eye is that of Hila Chefer, Shir Gur, and Lior Wolf, entitled “ Transformer Interpretability Beyond Attention Visualization”. As stated and justified in their article, these authors go way further than just visualizing attention weights: they propose a relevancy propagation rule to track relevant context across the layers of the network, then integrate the attention and relevancy scores, and finally combine the integrated results for multiple attention blocks. This setting, including the introduced relevance propagation strategy, considers the information flow through the entire network, not just the attention maps, resulting in explanations of outstanding quality in both linguistic and computer vision tasks.
Check out their Github repository for open-source code, details, and examples!