AI Algorithms Lifecycle Management and Collaboration
Background
In XMANAI we have set out to develop robust and insightful AI pipelines that can assist manufacturers in their everyday operations and decision-making processes. To achieve our goal, we are creating a collaborative environment in which the explainability of the ML models’ decisions lies at the heart of our AI pipelines design, development and roll out. Needless to say, in order for these AI pipelines to be properly configured, trained, evaluated, deployed and applied, constantly monitored, assessed and refined as needed, numerous other processes need to be in place.
Luckily, we are not alone in this venture. The AI landscape is vast, both in terms of academic literature but also open source tools and libraries that can be leveraged, either directly or indirectly for insights extraction. So, our first step was a deep dive into the state of the art of AI pipelines. What did this state-of-the-art analysis show? We learnt a lot about new technologies, processes, and tools – and we plan to use some of our findings directly into our XAI pipelines architecture (more updates coming soon…). But we also made some broader realizations about the way AI pipelines work (or should work), which helped us shape our own design – and we would like to share them.
Lessons learnt & challenges ahead
AI pipelines do not – and should not- end with a trained model
Problems and questions that emerge in production should be easy to be traced back to ensure that involved stakeholders can get the answer they need and/ or effectively and timely debug the issue. Model performance in production can differ from that in the experimentation settings or it can gradually deteriorate due to numerous reasons, so establishing feedback loops and ensuring all involved stakeholders are aware that the process does not end after successfully training and deploying a model, is critical. In XMANAI we will ensure that the trained model is not the end of the journey also through the provision of model explainability methods that will constitute a permanent link between the way the model was trained, what it has learnt and how this translates in production applications.
Explainability is not yet part of MLOps
MLOps is the intersection between ML and DevOps (development operations), offering practices for building, deploying and managing Machine Learning (ML) systems. Explainability is key to allow humans in the manufacturing sector to trust the decisions of the ML models, while also holding the model accountable for any wrong or rogue decision. Compliance with company policies, industry standards and government regulations are also among the benefits explainability can offer. And of-course we have the obvious benefits for data scientists in their efforts to improve model performance. Landscape analysis showed that even though XAI and MLOps are two domains gaining attention from both the scientific and the commercial communities, no established patterns and practices exist yet for their intersection.
Visualisation is not a step, it is an integral part of almost all steps of an AI pipeline
From data exploration and outlier detection, to model training and experiments comparisons, to production performance evaluation and explainability insights, to training-production data skew monitoring, different visualisations are leveraged. Data scientists, data engineers and business users all require targeted and diverse visualisation functionalities to be available, as visual understanding, interpretation and even questioning of input data, models, and results is extremely powerful and significantly more intuitive for users.
Collaboration, collaboration, collaboration
Collaboration among the stakeholders involved in the different stages of the development and deployment of AI pipelines is crucial. It accelerates understanding, prevents mistakes, facilitates debugging and easier transition from experimentation to production serving and finally enables thorough performance evaluation and meaningful feedback loops. So, does this mean it is straightforward to achieve? Not quite…
Starting from technical aspects such as granting access rights to different stakeholders for the various assets (datasets, models, pipelines, experiments, analysis results) to difficulties like ensuring that all relevant stakeholders have signed off on the model. Collaboration in terms of information flows can only have a positive effect, but collaborative decision-making introduces new risks and challenges if involved stakeholders are not provided with the information they require in a comprehensible manner for their needs and background.
Our first take on the XAI bundles
Figure 1 shows the architecture of the XMANAI AI Bundles, i.e. the mechanisms that will deliver the XAI pipelines and offer the tools and processes needed to handle their full lifecycle. Each of the outlined components (included in the high-level architecture) offers interfaces targeting the different needs of the XMANAI stakeholders both on an individual basis and when considering cross-team collaboration. Let’s get to know them.
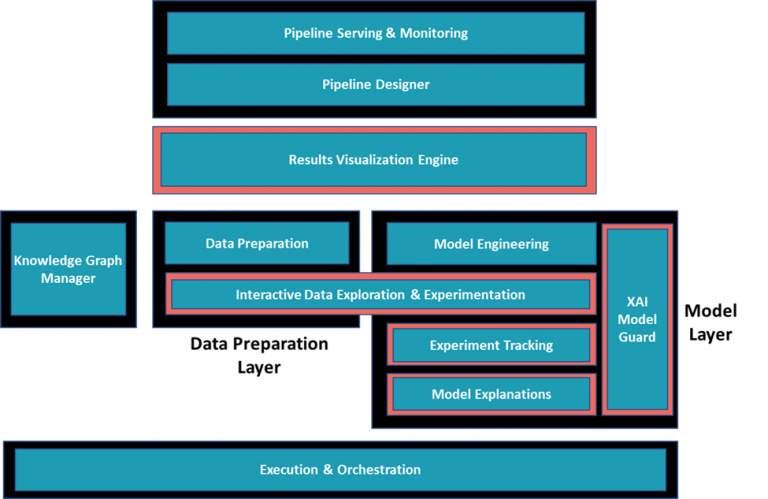
The Knowledge Graph Manager provides the semantic information that helps increase the explainability of the pipelines’ input data.
The Interactive Data Exploration and Experimentation tool shared between the Data Preparation and the Model layers, accounts for the fact that experimentation is inherent in data science, both when it comes to data and to models. The Data Preparation Engine on the other hand handles data preparation processes in a production setting.
The Model layer, apart from the already mentioned Interactive Data Exploration and Manipulation Tool, includes: the Model Engineering tool which provides the ML/DL model selection, configuration, and training functionalities, the Model Explanations tool which powers the explainability methods’ configuration, application and results (explanations) generation, the Experiment Tracking Engine that enables logging of experiments’ metadata (performance metrics, corresponding hyperparameters, and other artifacts) and performing comparisons and the XAI Model Guard that brings safeguarding mechanisms for the security and integrity of the trained AI models.
The Pipeline Designer is in charge of the creation and management of the AI pipelines and of enabling and coordinating the collaboration of different stakeholders (business users, data scientists, and data engineers) and team members across the various steps of the pipelines and The Pipeline Serving and Monitoring Engine is responsible for the deployment of the pipelines that are suitable for usage in production and for monitoring their performance to provide insights regarding their operation. The Execution & Orchestration Engine is responsible for the execution of the fully configured XAI Pipelines created by the XAI Pipeline Manager.
When it comes to visualization, the Results Visualisation Engine, allows results generated by the AI pipelines to be appropriately visualized and communicated to the business users. However, following the state-of-the-art gained insights, we want to make sure that visualization, visual exploration, and visual communication of results, explanations, and overall findings – which are constant needs throughout the process – are offered as needed when needed. That’s why numerous tools offer visualization features/ functionalities, as denoted by the bright outline used in Figure 1.
Where to now?
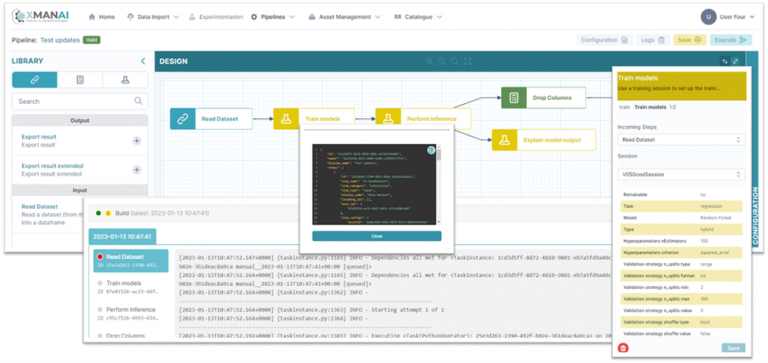
This was a brief introduction to our XAI bundles and the way we will bring our XAI pipelines to life! The Alpha release of our platform is already live, so stay tuned for updates & to see our tools in action! Till then, you can get a sneak peek from the screenshots in Figure 2.